Web Scraping techniques
** A handbook over the techniques you can use to extract data from web pages. Investigate web page's internals to find the most effective approach.**
This article introduces a quick summary of how you may investigate a website's structure and communication methods. Using these techniques will help you extract data more efficiently.
Developer tools
All modern browsers come tied with a set of development tools. Although these have been developed to build websites in mind, such tools can also analyze web pages and traffic.
For Chromium-based browsers, these developer tools can be invoked from any page by right-clicking and selecting 'Inspect' or using the shortcut CTRL + shift + I (or ⌘ + Option + I on macs). For Mozilla such tools can be opened by right-clicking at content and selecting 'Inspect element'.
Check out the information that can be gathered with developer tools and how to extract and use it in web scraping software.
CSS selectors
The basic web scraping method is to use CSS selectors. They allow you to get desired HTML element by ID, class, attributes, or type.
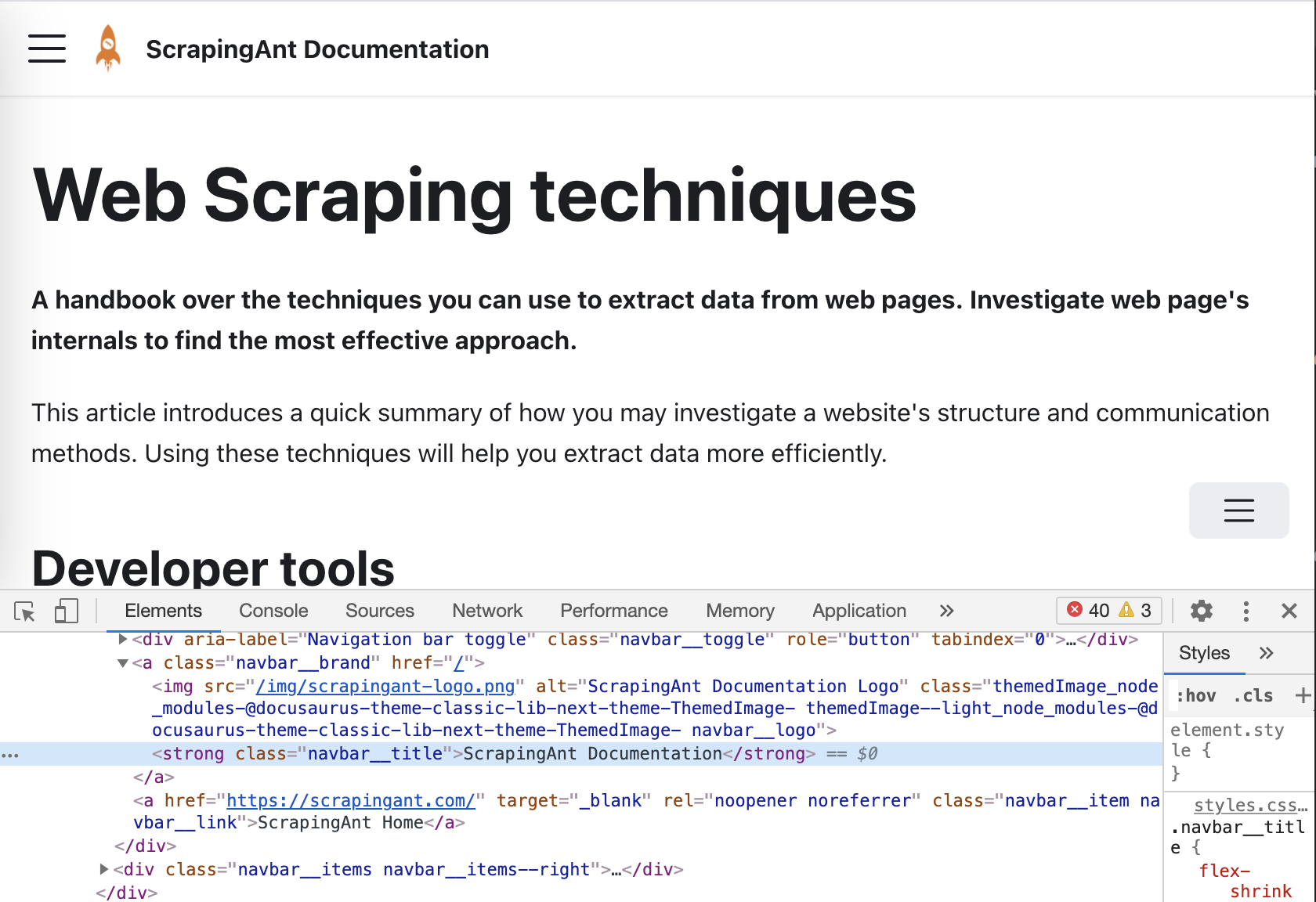
The image above illustrates an element (navigation bar title) that can be selected by the class name navbar__title.
Schema.org microdata
Schema.org is a collaborative, community activity with a mission to create, maintain, and promote schemas for structured data on the Internet, on web pages, in email messages, and beyond.
Schemes provided inside HTML content allow major search engines like Google, Bing, and Yahoo to better understand web pages' content and provide more accurate search results.
If a particular website uses microdata, you may find it in its <head> element. As an example, below, you can find a microdata 'Person' with properties name, url, and title.
<div itemscope itemtype="http://data-vocabulary.org/Person">
Name: <span itemprop="name">Oleg Kulyk</span>
Website: <a href="https://scrapingant.com" itemprop="url">scrapingant.com</a>
Title: <span itemprop="title">CEO</span>
</div>
Using this data may simplify the data extraction and avoid needed information search across the whole web page. Check out the Schema.org documentation to find out the proper keyword for search.
JSON-LD
Similar to Schema.org microdata, some sites use JSON for Linking Data (JSON-LD). Based on the JSON format, JSON-LD helps structure a web page's content to easy for humans and computers to read.
To check out if a website uses JSON-LD, check its <head> element using your browser's developer tools. You can find the JSON-LD data in a <script> element similar to the one:
<script type="application/ld+json" id="website-json-ld">
{
"@context":"http://schema.org",
"@type":"WebSite",
"name":"Company Name, LLC.",
"alternateName":"Best Company",
"url":"https://www.company.com"
}
</script>
Then, you can use the code in your scraper to extract the data or pass this code to ScrapingAnt API for running in the browser context:
const JSONdata = $('script[type="application/ld+json"]');
return JSON.parse(JSONdata.html());
Inspecting traffic (XHRs)
Sometimes the information you're looking for is not loaded while the initial page load. Or perhaps there is an API call or a Websocket connection that loads the data you need. To review these calls, you'll want to see what requests are needed to load a certain page. You can find out this and more in the Network tab. This is what it looks like:

Using XHRs, you can obtain an entire API's content without even requesting the page. Just find the XHR that requests the data you want and use it to retrieve the data in a neat, structured format.
Cookies and Local Storage
The HTTP protocol is stateless, but cookies and the WebStorage API allow it to keep context consistent over the session flow. Sometimes it may be convenient to load cookies from one browser session and pass it into another. To locate current page cookies, click on the lock icon on the left side of the browser's address input.

The WebStorage API might be helpful too for debugging and understanding the website internals. It often stores the current page state and supplemental information for the proper web page work. You can find it at the Application tab of the browser's developer tools.
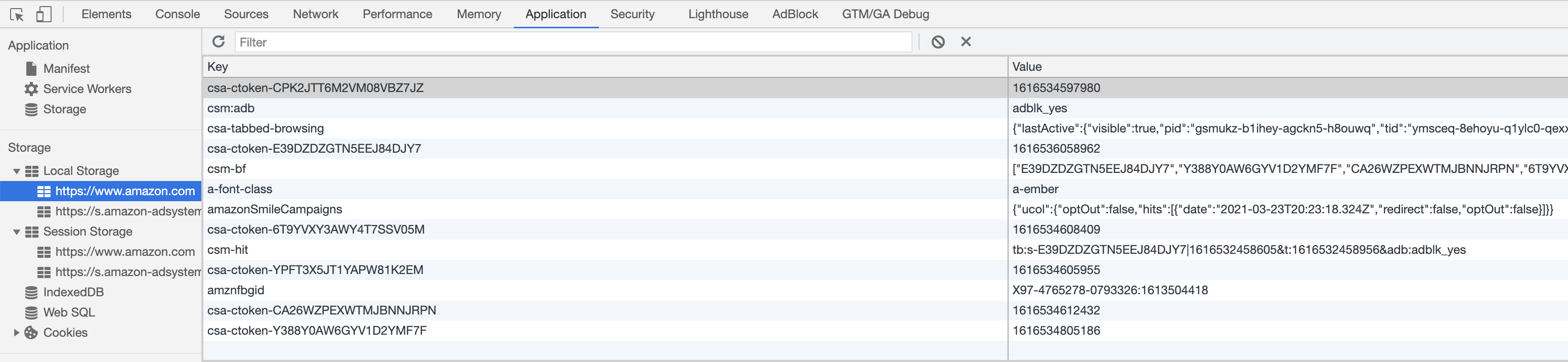
Internal JavaScript variables
Dynamic webpages use Javascript to load and process data retrieved from the data sources like CMS or a custom backend. You can find internal JavaScript variables in the code placed or loaded in a <script> tag in a web page's <head> element.
To use internal variables, you need to load the browser page (which supports developer tools or provides programmatic access, like Puppeteer or Playwright). Once it is loaded, you can return the variable that contains it using return {variable_name} (within the page context) or type the variable name in the console.

Browser extensions
You can add a lot of additional features to the browser using data extraction and web scraping extensions. Our favorites:
- DFPM - don't fingerprint me, an extension that monitors how the website recognizes your device, useful when you're getting blocked, and great software to check how modern anti-scraping techniques work
- XPath helper - allows you to see the exact output of an XPath directly in your browser, a bit more visual and assisted XPath tool
- VPN and proxy extensions - there are plenty to choose from here with lots options. Pretty helpful to check the cross-country site versions
Postman, the REST client
Sending requests without writing a single code line!
Postman allows you to execute requests and review the request results without any technical knowledge. The mess of parameters does not overload the UI, and you can store requests for later use. Just create a new collection and save the request there.
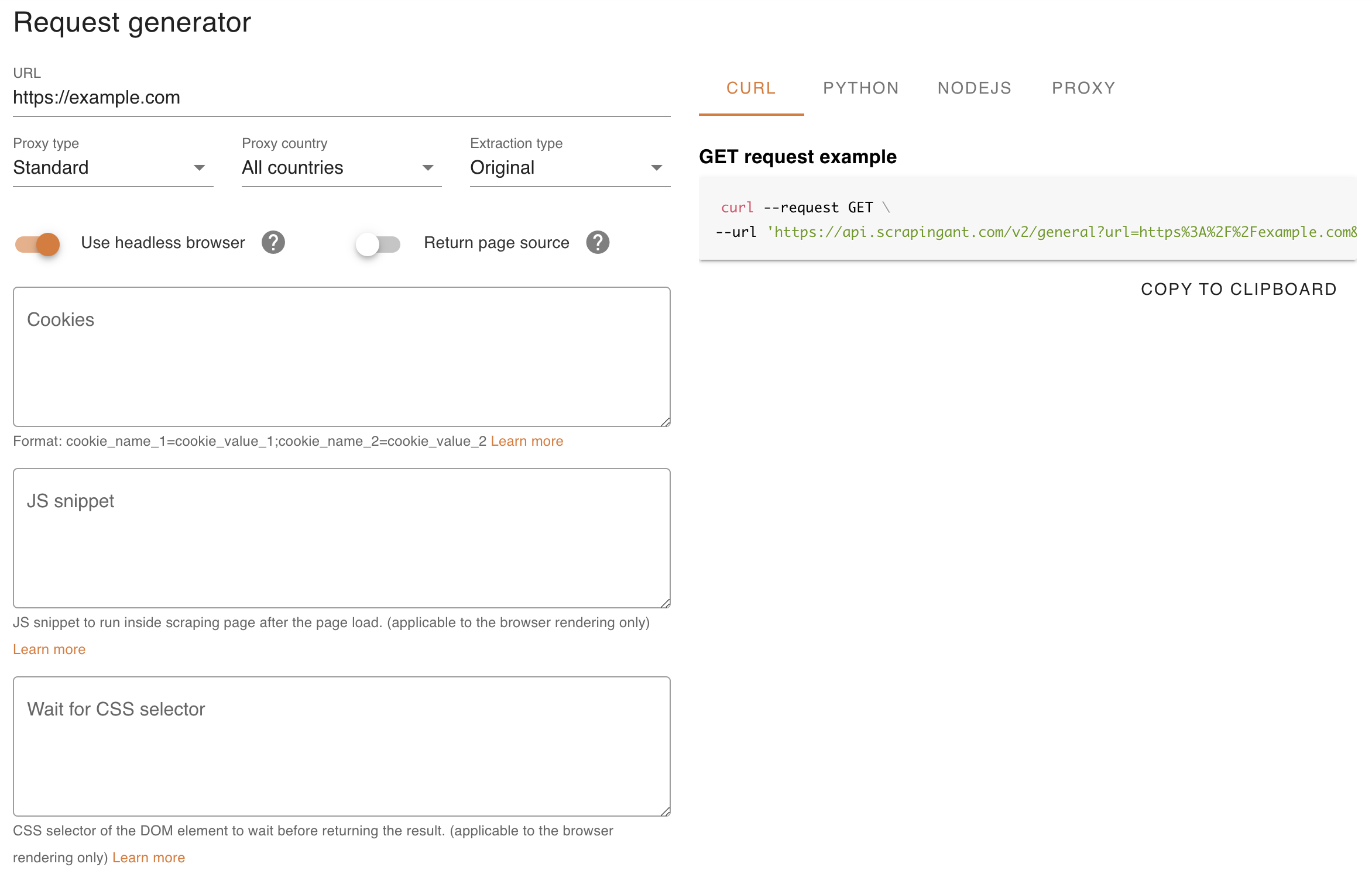
ScrapingAnt request executor
To check page rendering via the headless browser, you can use ScrapingAnt's request executor. It allows you to pass custom cookies, set proxy settings, and apply custom JavaScript to run in the browser.
UI is pretty intuitive and has lots of features. You have the basic information about your requests as the URL, its parameters, and cookies to fill in.
It's free to start using the request executor. Just follow the Login page to try it out with the most reliable Web Scraping API.